クラスタリングでクエリを効率化
高速な処理を実現するSnowflakeのアーキテクチャ
以前の 『Snowpipeでデータ分析基盤Snowflakeへデータロードする方法』 や 『Snowflakeのウェビナーで初登壇した話』 の記事で触れている通り、弊社ではデータ分析PFとしてSnowflakeを活用しています。
余計なことを考えずに膨大なデータを高速に処理できる優れたサービスで、使った分だけの従量課金制というのもとてもありがたいです。とはいえ、それなりに利用していて (円安💸の影響もあり) それなりのコストがかかっているので、この度コスト削減できないかを調査してみました。
Snowflakeのコスト
Snowflakeのコストは
-
コンピューティングリソース
-
ストレージリソース
-
データ転送リソース
の利用にかかるコストから構成されています。
それぞれどのようにコストが発生するかは、Snowflakeのドキュメントにわかりやすく記載されていますので、ここでは割愛させていただきます。これを拝見するに、いろんなところでコスト削減ができそうです。例えば、コンピューティングリソースでは、ざっくりと (ウェアハウスのタイプ) x (クエリの実行時間) でコストが算出されますので、きちんとデータ構造を設計したり効率の良いクエリを実行することがコスト削減に繋がります。
今回の記事では、データ分析基盤を構築する時に手がまわっていなかった、クラスタリング機能を活用することによりコストが削減できた話を実例を交えて記載させていただきます。
マイクロパーティションとプルーニング
クラスタリングとは、「データを特定のキーでソートして配置すること」です。Snowflakeにおけるクラスタリングでどのようなことが行われているかを理解するには、Snowflakeの高速な処理を実現しているマイクロパーティションとプルーニングが前知識として必要になります。
これまた非常にわかりやすくSnowflakeのドキュメントやブログに記載されていますので、詳しい内容は割愛しますが、ざっくりと、マイクロパーティションによりデータを細かく分割して保存し、プルーニングによってどのマイクロパーティションは読まなくていいかを判断してI/Oを減らすということが行われているようです。Snowflakeではこれが何の設定をせずとも自動で行われています。
クラスタリング
マイクロパーティションでは基本的にデータを INSERT した順番に分割して格納するので、分析したい軸によってはプルーニングをしても全てのマイクロパーティションを読み込んでしまうことになりかねません。そこで、任意のキーでソートしてマイクロパーティションを再編成しましょう という機能がクラスタリングです。Snowflakeでは新しいデータが INSERT されるたびにクラスタリングしてくれる、自動クラスタリングという機能もありますので、一度設定してしまえば定期的にメンテナンスしてあげる必要もありません。
ただし、マイクロパーティションの再編成には所要時間に比例したコストがかかりますので、たまにしか検索されないテーブルをクラスタリングするとクラスタリングにかかるコストの方が高くなってしまう可能性もある点には注意が必要です。
いざ実験
クラスタリングキーを設定するテーブルの決定
クラスタリングによるマイクロパーティションの再編成にどの程度の時間を要するか、どの程度パフォーマンスが改善されるのか、を試算するのが難しかったため、ひとまず “WHERE句が含まれている” かつ “スキャンしているパーティションが多い” クエリを調べてみました。
SELECT query_id, ROW_NUMBER() OVER(ORDER BY partitions_scanned DESC) AS query_id_int, query_text, total_elapsed_time/1000 AS query_execution_time_seconds, partitions_scanned, partitions_total FROM snowflake.account_usage.query_history Q WHERE warehouse_name = '<WEARHOUSE_NAME>' AND TO_DATE(Q.start_time) > DATEADD(day,-10,TO_DATE(CURRENT_TIMESTAMP())) AND total_elapsed_time > 0 AND error_code IS NULL AND partitions_scanned IS NOT NULL AND query_text LIKE '%WHERE%' ORDER BY partitions_total DESC LIMIT 50;
そして、上記クエリで得られた結果から、日々のアクセスが多くて最も効果がありそうなテーブル 1つにクラスタリングキーを設定してみることにしました。
実はこの時、クエリ結果の上位にあがったテーブルにはマテリアライズドビューでないビューが多く含まれていました。しかし、非マテリアライズドビューはクラスタリングをサポートしていませんので、ビューで定義すべきなのかを改めて見直してみるのもありかもしれません。
クラスタリングキーの設定
クラスタリングキーの設定はわずかクエリ 1行です。
ALTER TABLE <TABLE_NNAME> CLUSTER BY (<COLUMN_NAME>);
この時、同時に自動クラスタリングの設定まで行われます。
実際に確認してみると、クラスタリングキーが設定され、自動クラスタリングがONになっていることが確認できました。
SHOW TABLES LIKE '<TABLE_NNAME>';

なお、この瞬間から裏側ではマイクロパーティションが再編成されていますが、この間も当該テーブルに何の制約もなく操作可能なので、設定するタイミングを選びません。👏
クラスタリング情報の確認
再編成中でも制約なくテーブルを操作できてしまう一方で、本当に再編成されているのかが気になります。🤔
前述の通り、クラスタリングされるとクラスタリングキーに設定した項目は、マイクロパーティションごとに異なった範囲の値を持つことになります。つまり、重複した値を持つマイクロパーティションの数が減少します。この「重複した値を持つマイクロパーティションの数」をクラスタリング深度と呼び、深度が減ってればクラスタリングされていると言えます。
ただし、ドキュメントには下記の通り、クラスタリング深度が適切なクラスタリングの絶対的な尺度となるわけではなく、パフォーマンスの改善をもって判断すべきとの記載がありましたので、ここは留意しておいた方がよい点です。
The clustering depth for a table is not an absolute or precise measure of whether the table is well-clustered. Ultimately, query performance is the best indicator of how well-clustered a table is:
・If queries on a table are performing as needed or expected, the table is likely well-clustered.
・If query performance degrades over time, the table is likely no longer well-clustered and may benefit from clustering.
それでは、クラスタリング情報を見て確認してみましょう。
SELECT SYSTEM$CLUSTERING_INFORMATION('<TABLE_NAME>', '<CLUSTERING_KEY>');
クラスタリング設定直後、テーブルの平均クラスタリング深度は 10,000弱 という非常に大きな値でした。
{ "cluster_by_keys" : "<CLUSTERING_KEY>", "total_partition_count" : 174605, "total_constant_partition_count" : 2044, "average_overlaps" : 9786.6513, "average_depth" : 9764.6297, "partition_depth_histogram" : { "00000" : 0, "00001" : 2044, "00002" : 0, "00003" : 0, "00004" : 0, "00005" : 0, "00006" : 0, "00007" : 0, "00008" : 0, "00009" : 0, "00010" : 0, "00011" : 0, "00012" : 0, "00013" : 0, "00014" : 0, "00015" : 0, "00016" : 0, "00256" : 213, "08192" : 21141, "16384" : 151207 }, "clustering_errors" : [ ] }
これが時間の経過とともに減少し、翌日確認してみると平均クラスタリング深度は 1強 に改善されました。🎉
{ "cluster_by_keys" : "<CLUSTERING_KEY>", "total_partition_count" : 423654, "total_constant_partition_count" : 422608, "average_overlaps" : 0.0412, "average_depth" : 1.0276, "partition_depth_histogram" : { "00000" : 0, "00001" : 422177, "00002" : 10, "00003" : 22, "00004" : 77, "00005" : 188, "00006" : 213, "00007" : 206, "00008" : 223, "00009" : 158, "00010" : 149, "00011" : 65, "00012" : 79, "00013" : 32, "00014" : 0, "00015" : 8, "00016" : 0, "00064" : 47 }, "clustering_errors" : [ ] }
どうやらクラスタリングされているようですので、クエリのパフォーマンスがどの程度改善されたか を実際にクエリを実行して確認してみます。(TASK名を隠してしまっているので信憑性が薄くなりますが…) 同TASKの実行時間がおよそ 70分から 3分に激減していました。🎊

クラスタリング前

クラスタリング後
クラスタリングのコスト
クラスタリングすることでクエリパフォーマンスが改善され、クエリにかかるコストは激減したのですが、忘れてはいけないのがクラスタリング自体のコストです。これに膨大なコストがかかっていては元も子もありません。
確認してみると、クラスタリングキーの設定時にはかなりコストがかかっているものの、日々のクラスタリングにはほとんどコストがかかっていません。20日と月末には1ヶ月分の視聴データを操作していますので、少しコストがかかっているようですが、それでも日々のクエリパフォーマンスの改善による削減分を上回ることはありません。
SELECT TO_DATE(start_time) AS date, database_name, schema_name, table_name, SUM(credits_used) AS credits_used FROM snowflake.account_usage.automatic_clustering_history WHERE start_time >= DATEADD(month,-1,CURRENT_TIMESTAMP()) GROUP BY 1,2,3,4 ORDER BY 1 ASC;
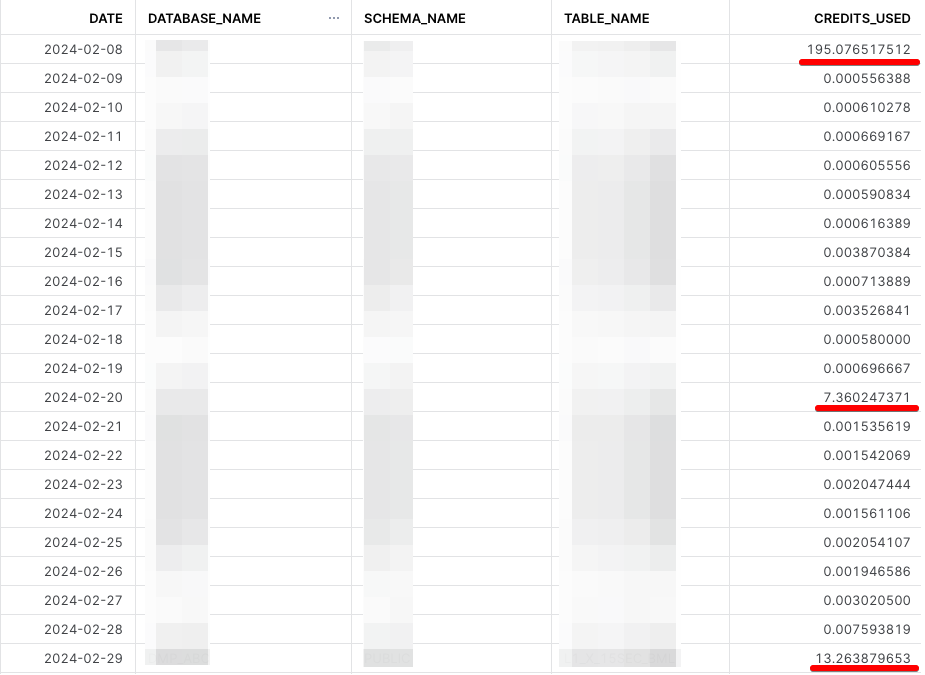
ちなみに、クラスタリングのコストはSnowflakeが提供する AUTOMATIC_CLUSTERING という名前のウェアハウスで表示されるとのことですので、Snowflake提供のリソースで動作しているものと思われます。
Automatic Clustering costs show up as a separate Snowflake-provided warehouse named AUTOMATIC_CLUSTERING.
おわりに
ついつい後回しになりがちなコスト見直しの一環しとして、クラスタリングを行ってみました。コストが削減されただけでなく、便利なだけに普段意識しなくなっていたSnowflakeのアーキテクチャの理解も深まり、やってよかったことしかありません。
今回は費用の削減を行いましたが、次は運用負担の軽減に有効な打開策を講じたいところです。💪
