データ構造の違いでクエリパフォーマンスに大きな差が出た話
皆さん、データを扱う際にどのくらいクエリパフォーマンスに気を遣って実行しているでしょうか?
特に弊社で利用しているSnowflakeなんかは時間単位での従量課金になっているので、パフォーマンスに差が生まれるとその分課金額も大きく変わってきます。
今回はそんなクエリパフォーマンスがデータ構造の違い(縦持ち/横持ち)によって大きく変わった話をしたいと思います。
データの縦持ち/横持ちとは
データの縦持ちと横持ちというのはテーブルの設計思想の違いで、具体的には以下のような違いがあります。(※データは架空の値です)
- 横持ち: 行と列にそれぞれ異なる項目を配置し、行と列の対応で情報を表すデータ構造です。
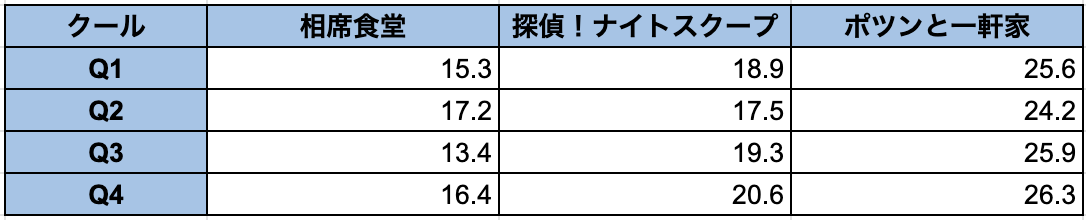
- 縦持ち: 列に配置された項目に対し、対応するデータが縦に追加されていく形式となっています。
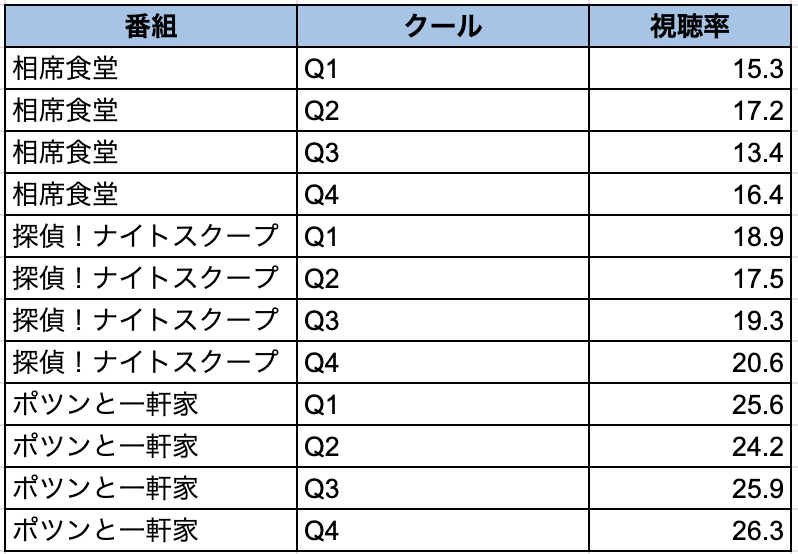
横持ちはExcelなどで扱われ、視認性に優れているため、人がパッと見て理解しやすいのに対して、縦持ちはDWHやBIツールでコンピュータがデータを処理する際に扱いやすいです。
では、次にそれぞれのデータ構造でクエリパフォーマンスにどのくらいの影響があるのか確認してみます。
クエリパフォーマンスの比較
今回はとあるログに縦持ちと横持ちのIDテーブルを結合してパフォーマンスを比較してみたいと思います。(Snowflakeで実行)
用意したテーブル
-
ID_LISTテーブル(横持ち)
A〜EのカラムにIDが入っており、COMMON_IDにはそれらのIDに対する共通IDが入っております。
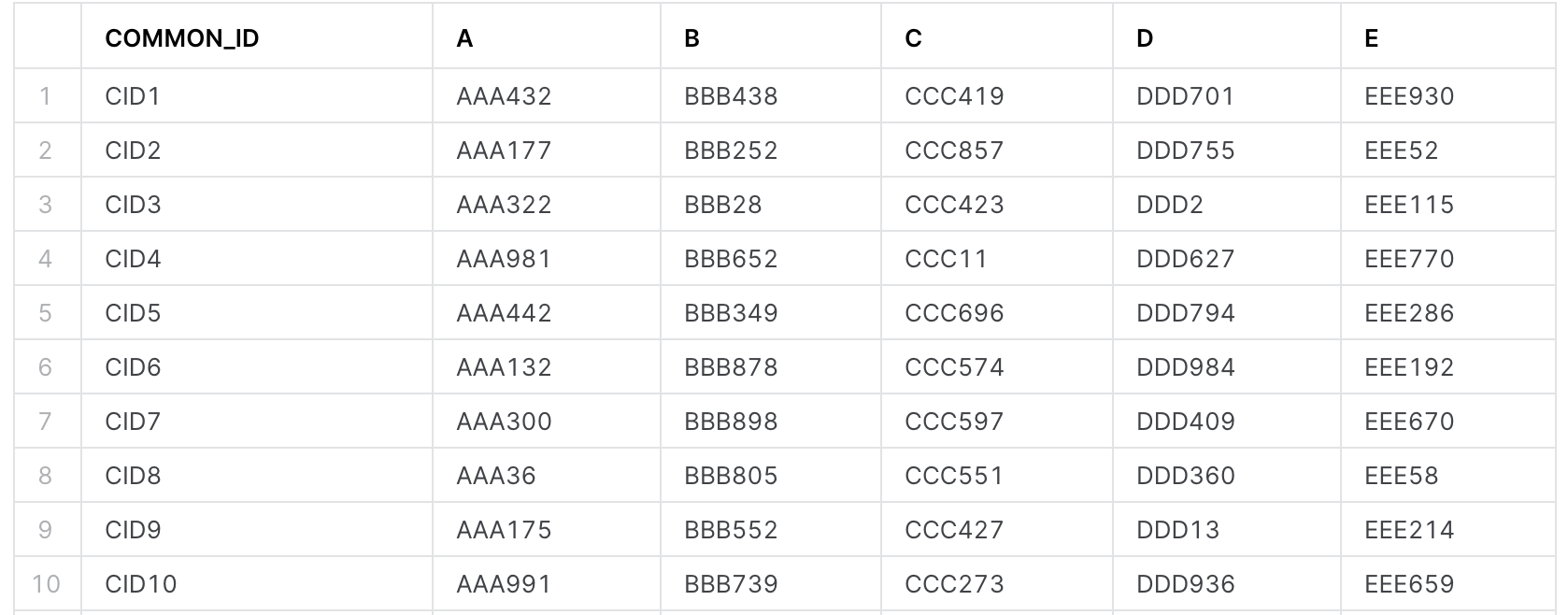
-
UNPIVOT_ID_LISTテーブル(縦持ち)
ID_LISTテーブルをUNPIVOTして縦持ちに変換したもの。

-
LOGテーブル
COLUMN_IDがID_LISTテーブルのA〜Eの各カラム名に対応しており、VALUE_IDはそのカラムの要素に対応しています。
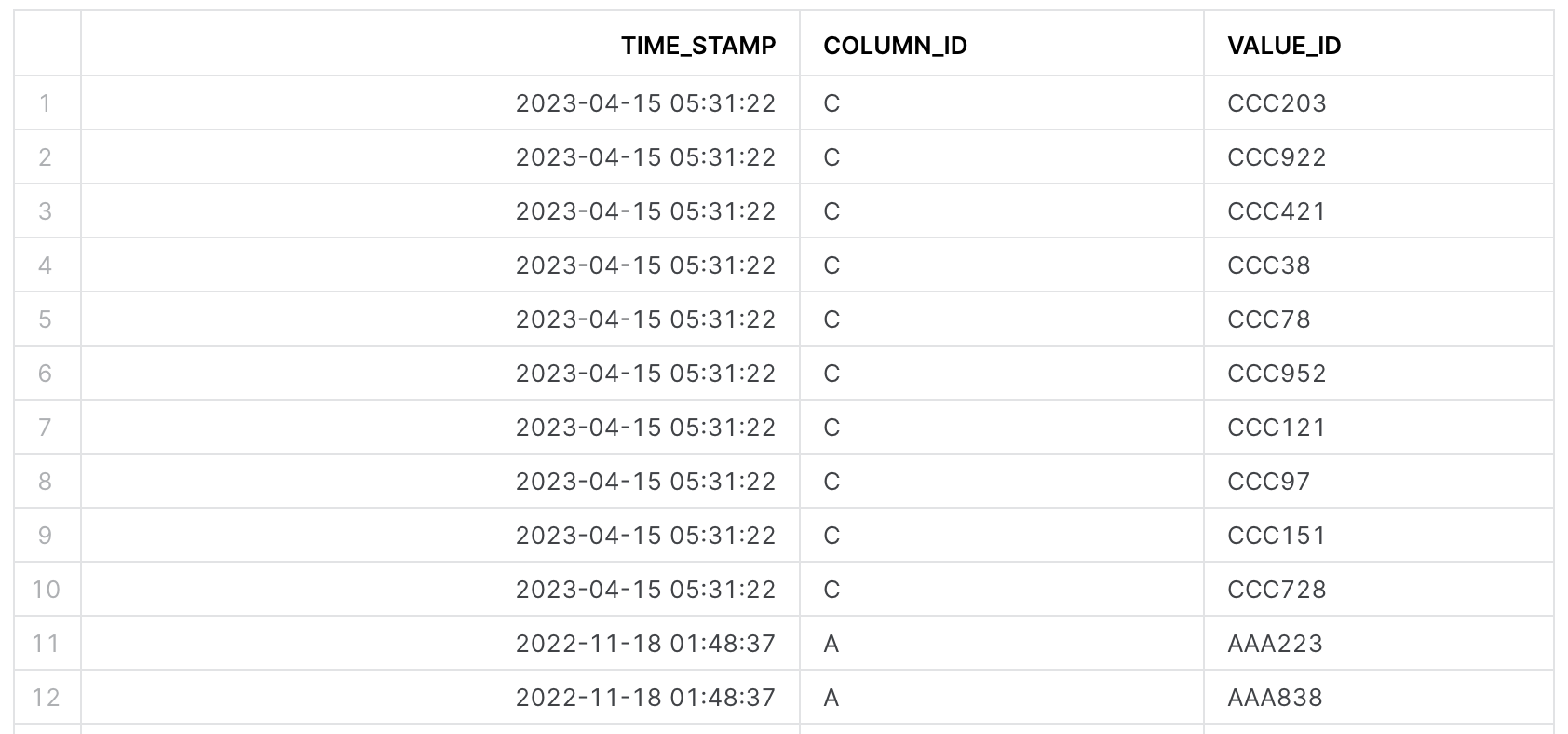
データの結合とパフォーマンスの比較
今回はLOGテーブルのVALUE_IDをCOMMON_IDに変換するというシチュエーションを考えたいと思います。
LOGテーブルとID_LISTテーブル(横持ち)の結合
-
実行したクエリ
SELECT TIME_STAMP, COMMON_ID FROM LOG INNER JOIN ID_LIST ON CASE COLUMN_ID WHEN 'A' THEN A = VALUE_ID WHEN 'B' THEN B = VALUE_ID WHEN 'C' THEN C = VALUE_ID WHEN 'D' THEN D = VALUE_ID WHEN 'E' THEN E = VALUE_ID END;
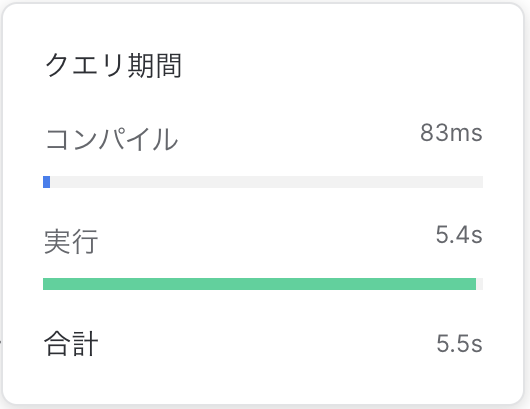
- クエリパフォーマンス
LOGテーブルとUNPIVOT_ID_LISTテーブル(縦持ち)の結合
-
実行したクエリ
SELECT TIME_STAMP, UNPIVOT_ID_LIST.COMMON_ID FROM LOG INNER JOIN UNPIVOT_ID_LIST ON LOG.COLUMN_ID = UNPIVOT_ID_LIST.COLUMN_ID AND LOG.VALUE_ID = UNPIVOT_ID_LIST.VALUE_ID;
- クエリパフォーマンス
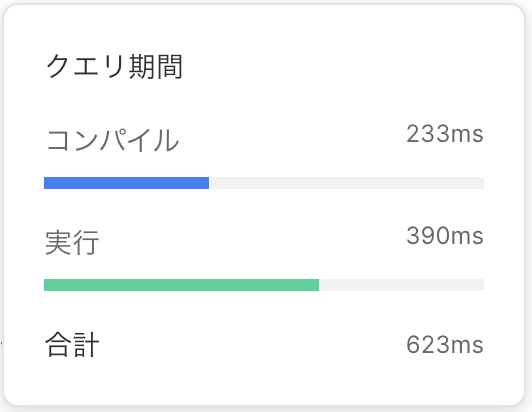
ということで実行時間が5.4s→390msとなんと約1/14になりました!
考察
LOGテーブルに対して縦持ちと横持ちのテーブルを結合してパフォーマンスを比較したところ、縦持ちテーブルの場合の方がパフォーマンスが高くなりました。
原因としては、
-
横持ちテーブルと結合する際にはCASE文を利用しており、この評価に時間がかかっている。
-
今回利用したSnowflakeを始めとするデータウェアハウス(DWH)は列指向データベースと呼ばれており、列単位でデータを読み込むため、読み込む列が少なくて済む縦持ちテーブルの方がパフォーマンスが高くなった。
が考えられます。
他にも原因はあるかもしれませんが、総じて言えるのはDWHやBIツールを用いたデータ分析を行う際には縦持ちテーブルの方があらゆる点でオススメということです。
ちなみに今回はデモとして各テーブル10,000レコードずつ(UNPIVOT_ID_LISTテーブルは50,000レコード)と、そこまで大規模ではないデータセットを用いたので、大きなパフォーマンス差にはなりませんでしたが、以前もっと大規模なデータセットを用いた際は横持ち→縦持ちに変換することでクエリ実行時間が2時間以上→1分程度まで大幅に改善したことがあります。
まとめ
縦持ちテーブルと横持ちテーブルの違いについて触れ、実際に分析に利用した際のパフォーマンスを比較しました。
比較した結果、縦持ちテーブルのほうがパフォーマンスが高く、クエリもシンプルになるため、分析に適した構造ということを確かめることができました。
特にアドホックな分析などで面倒くさがって、ちょっとした手間を惜しむことで今回のような大幅な違いに繋がる場合もあるため、クエリのパフォーマンスは常に意識できるようになると良いですね。
