LLMと自前データを組み合わせたい
LLMの爆発的な普及
いやー、2023年はLLMの年ですね。世はまさに大LLM時代という感じですね。(そもそもLLM自体が大やろ、というところもありますが)
LLMかAIが漢字一文字で表現できれば、今年の漢字はそれで決定ですね(?)
まあ実際は「復」とか「活」とかだと思いますが…
各社の方々と交流したりブログを見たりとかしていると、なにがしか触ってみていただいている方も非常に多いです。SlackやGoogle Chatのような利用しているChatサービスへのインテグレーションとしての実装とかが多い印象があります。
加速するワガママ
まあでも、人間は(AIと違って)ワガママですから、すぐに慣れてもっと上を目指したくなるものですよね。LLMに投げかける質問も、物足りなくなってきてだんだんパーソナライズされた内容を聞けるといいな…なんて思うようになったりとか。
例えば「8/10に浜松町まで出張があるんだけど往復運賃と出張手当の額を教えて」的なことを回答できるようになってきたらもうそれは秘書ですよね。
もしこういうことをしたくなったとしたらどうすればいいんでしょう?
往復運賃とかは他社の乗り換え案内的なサービスと連携してどうこう、でいけそうだな…という所感があるとして、出張手当なんて完全にこちらから内規のデータ渡さないと無理でしょうね、くらいまではLLMを知っていようがいまいがなんとなく見当のつくところです。
そこで、今回はどうやったら自前データを活用してLLMと組み合わせられるか?についての方法論をまとめていこうと思います。
思ったより長くなりそうなので、本記事ではまず仕組み的にどのようにするかから入ります。実際どういう実装をしたらどういう結果を得られるのか、みたいな話は次回に回します。
こういう記事を書くときに非常に難しいのですが、書いていると色々言いたくなってくるものの、 補足を入れまくると全体像がボヤけてしまう ので、ここではいったん駆け抜ける形で俯瞰することを目指します。
LangChainの話
早速少し脇道に逸れてしまうのですが、まず第一に、特にPythonでLLMを活用する文脈においてまず使うべきであろうライブラリがLangChainです。
LangChainについては私が初めて調べたとき、それっぽくまとめてある記事は多いものの、正直何が出来るのかよくわかりませんでしたが、 端的に言うと、LLMを活用するにあたって使うであろうものが一式揃っているライブラリです。
例えば、ChatGPTのように以前の人間側の発言とAI側の回答の履歴を参考にしながらチャットのようにやりとりをしたいとしたとき、
一般的には過去の発言を保存しつつ再度LLMに投げかける、ということになるのですが、そのための記憶に有用な Conversation buffer memory が用意されていたり、さらにいうと過去のn個に絞るなどの条件を付した Conversation buffer window memory などもあったりします。
今紹介したのがLangChainのMemory系モジュールの話ですが、その他にもPDFやMarkdown等のドキュメントを読み込んだ上でsplitして使いやすい形にするData Connection系モジュールなど、 様々な便利ツールが内包されています。
数多のLLMモデルのwrapperも内包しているので、使用するLLMを切り替えるのも簡単です。 対応しているLLMを確認するには、LangChainのLLM一覧ページが便利です。
というわけで、本ブログでLLMの話をするときには確実にLangChainが自然に登場することになると思います。
LLMで内部ファイルを利用するための方法論
さて、本題のLLMで内部ファイルを活用するためにどうするか…ですが、「まさに」なドキュメントがLangChainのブログに上がってます。
Tutorial: ChatGPT Over Your Data
というわけで、これをもう少しかみ砕いて説明します。ちなみにこの記事自体が半年前のものとはいえかなりアップデートが激しい分コードなどはちょっと情報が古いので注意が必要です。
ベクターストアへのロード
まず、内部ファイルと呼んでいるドキュメントの類をすべてベクターストアにロードします。
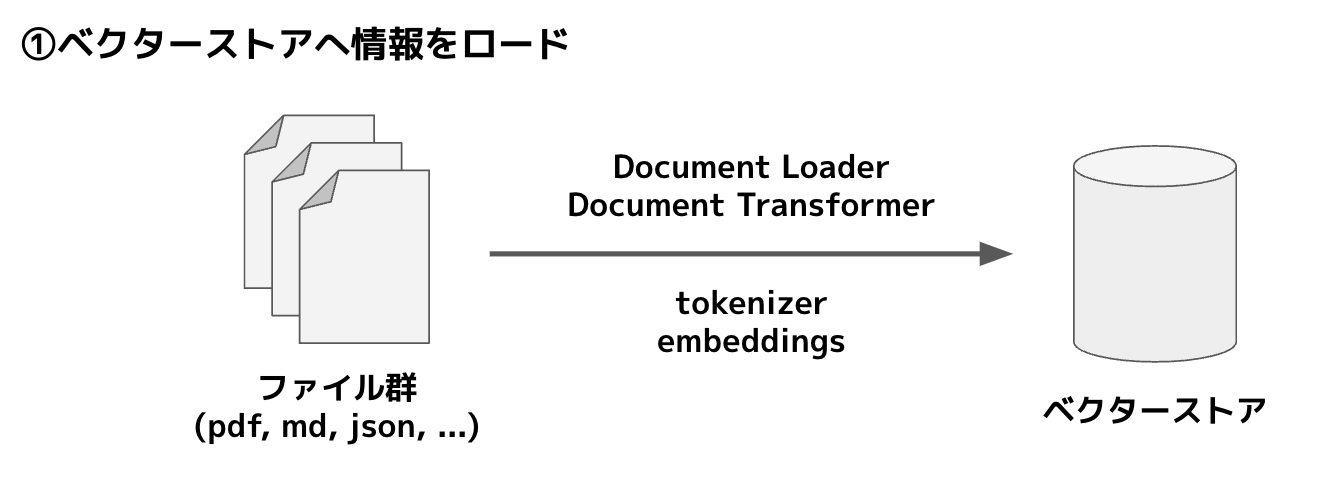
データソースをテキストにして、チャンクに分け、embeddingしてベクターストアにロードします…というとこれだけではなかなかわかりにくいかもしれません。
チャンクに分ける=細切れにする、くらいの感じです。で、問題はembeddingしてベクターストアにロード、だと思いますが、embeddingというのはこの細切れをベクトルに変換するということです。
このembeddingという作業を行うものとしてはword2vecが有名で、これは聞いたことがある方もいるかもしれません。いわゆる単語の足し算・引き算ができるということでわかりやすいのでよく取り上げられがちです。 King - Man + Woman = Queen ってやつです。
理屈はわかったからembeddingはどうやってやるねん、という話ですが、多くのLLMモデル提供社があわせてEmbeddings APIを提供していて、たとえばOpen AIでもEmbeddings APIを提供しています。
なので、LangChainであれば
from langchain.embeddings import OpenAIEmbeddings
のようにして利用できたりするわけです。
そしてLangChainがあれば「データソースをテキストにして、チャンクに分け」も「ベクターストアにロード」もData Connectionモジュールでできてしまいます。だんだんLangChainの強さが見えてきたのではないでしょうか。
ちなみに、ベクターストア自体はドキュメントに変更がなければ毎回作る必要も無いので、PoCレベルであれば pickle とかでdumpして保存、とかで良いかと思っています。
毎回Embeddings APIを叩くと当然ですが課金されるので注意が必要です。
データをクエリする
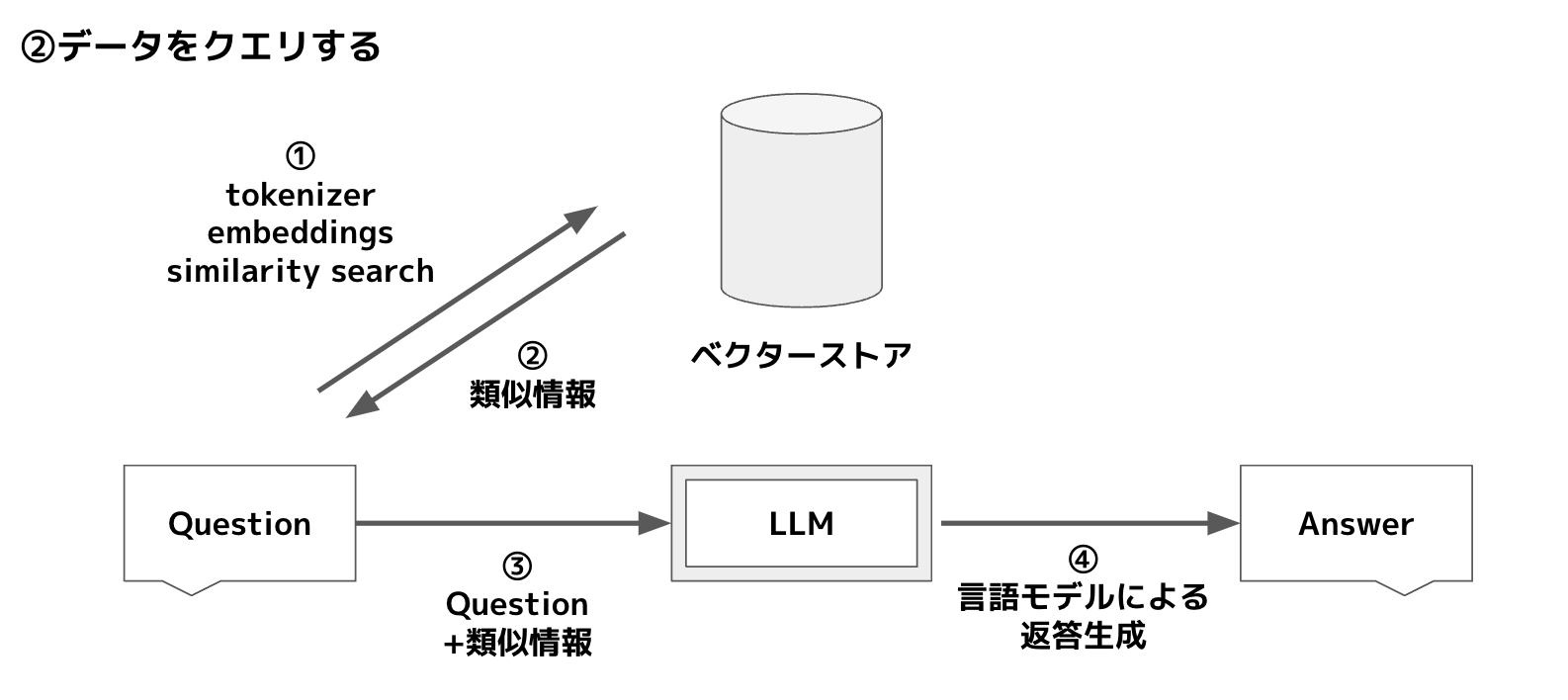
ベクターストアの準備が出来たら、あとはそれを利用するだけですが、このときどのようなことをするかというと、
まず、ベクターストアに対して質問から類似度の高い情報を抜きます。ここはLLM側でなくローカル環境での動作です。(similarity search)
そして、抜いてきた類似度の高い情報と質問をあわせてLLMに投げることで、LLMに会話っぽく答えをもらえる、という仕組みです。
LangChainでは RetrievalQA ないしは会話型の場合は ConversationalRetrievalChain を利用することでこのあたりの処理を簡単に行えるかと思います。
実装としては、QA using a Retrieverのページが参考になります。
ちなみに「類似度の高い情報を抜く」ステップについては、similarity search を行うことで実際に見ることが出来るのでやってみると面白いと思います。
まとめ
本記事ではLLMを活用して内部で保有しているデータを用いた回答が得られるようになるまでの方法論をまとめました。
2枚の画像をまとめるとこうなります。

LLMはなんとなくでも動くのですが、活用にあたって様々な予備知識があったほうがより正しく使いこなせるものかと思います。
今回触れることのなかったプロンプトテンプレートによるプロンプトエンジニアリングの効率化など、まだまだ掘ろうと思えば山ほど掘れそうです。
本ブログでLLMについてどこまで扱うかは未定ですが、とりあえず次回はこれを踏まえて、実際にどのようにデータを活用できるかについて実装に深く触れていこうと思います。
実装に入るといよいよLangChainが大活躍している様が見られると思います。
ちなみに最近ではLangSmithなんて便利なものも出てきていまして、活発に開発が進められている様子が伺えます。一方で、情報のアップデートがめちゃくちゃ早くて、deprecatedな内容も多くなりがちなので情報収集時は注意が必要ですね。
