Lookerでの配列データ・階層化データの扱い方
Lookerで配列データを扱いたい
皆さんLooker使ってますか?私は使っています。
とても便利です。データガバナンスも効かせられるし、BI初心者にも使って貰いやすいし、夢のようなプロダクトですよね。(もっとも、企業レベルでの導入が求められるので、少し利用までのハードルが高いですが…)
今回は、Lookerで配列データを扱う際の方法についてまとめます。
配列データとは
本記事で言うところの配列データとは、一つのカラム内に複数の値を持つものを指すことにします。
そういったケースは本来的にはRDBであればテーブルを複数立てて one-to-many な関係を持たせるのがベストプラクティスかと思います(リレーショナル・データベースですからね)が、もっと柔軟なデータ格納をしたいとか、わざわざテーブルを立てるほどでもない…といったシーンもよくあるということで、各種DBエンジンにおいて対応が進められてきました。
たとえば、PostgreSQLではガッツリ配列型としてサポートされています。MySQLでは直接的な配列型はないと認識していますが、JSON型として階層化データがサポートされており、こちらを活用できます。
皆さんが大好きな(?) BigQueryでもARRAYはサポートされています。特にこういったOLAPなDBではどうしても必要になりますよね。
というわけで、配列のカラムを含むデータが皆さんの手元にある、というのはよくある話かと思います。
SQLで配列データを扱う方法
Lookerでの配列データの扱い方の前に、SQLでどのようにこの配列データを扱うのかについて考えます。
例えば、購買データを想像しましょう。購買ID・会員ID・商品IDの配列の3カラムからなるテーブル purchases を考えます。
| transaction_id | member_id | item_ids | | -------------- | --------- | -------------- | | 1 | 1 | ["foo", "bar"] | | 2 | 2 | ["foo"] | | 3 | 1 | ["buz"] |
このとき、商品ID毎に購入数を調べたいとしたらどのようにクエリを書けば良いでしょうか?
PostgreSQLでも、BigQueryでも、 UNNEST を使うことによって対応します。
例えば、BigQueryの場合、
SELECT item_id, COUNT(*) as purchase_count FROM ( SELECT transaction_id, member_id, item_id FROM purchases, UNNEST(item_ids) as item_id ) GROUP BY item_id;
のようにすることで、 item_ids が複数の場合はそこをバラしてそれ以外のカラムは同じ値のテーブルからのSELECTが可能となります。(上記クエリでは SELECT するのは item_id のみでも大丈夫です)
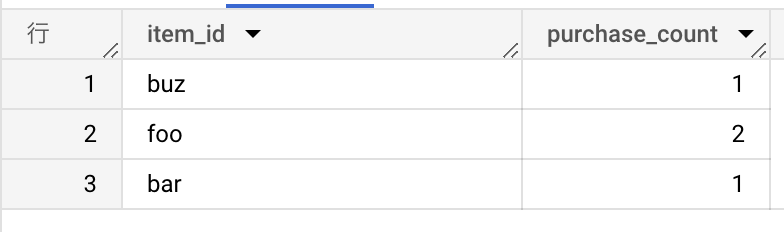
と、こんな感じでとても便利なので、DBを用いて分析を行う場合、UNNEST は使いこなせるようになっておいたほうが良さそうです。
Lookerで配列データを扱う方法
いよいよLookerで配列データを扱う場合について扱います。
要するに、 UNNEST すればいいわけですが、どのようにすれば UNNEST できるかについては、 Looker公式ドキュメントの、「BigQueryのネストされたデータ(繰り返しレコード)」のページがかなり参考になります。
ちなみに、 「ネストされたレコード」はJSONのような階層型データ を指し、 「繰り返しレコード」は配列データ を指します。「ネストされた繰り返しデータ」は、階層型データの配列…ですね。このあたりの言葉が結構紛らわしいですよね。
それはさておき、Lookerで扱う場合は、 model の explore で join するときに UNNEST を使う方法がスマートです。
上記ドキュメントの例では、
explore: persons { #Repeated nested object join: persons_cities_lived { view_label: "Persons: Cities Lived:" sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;; relationship: one_to_many } #Non repeated nested object join: persons_phone_number { view_label: "Persons: Phone:" sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;; relationship: one_to_one } }
となっていますね。
このように、 join 内の sql で UNNEST しながらJOINを走らせ、 view は別途この join 中の as で定義した名前に応じて
view: persons_cities_lived { dimension: id { primary_key: yes sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;; } dimension: place {} dimension: numberOfYears { label: "Number Of Years" type: number } measure: place_count { type: count drill_fields: [place, persons.count] } measure: total_years { type: sum sql: ${numberOfYears} ;; drill_fields: [persons.fullName, persons.age, place, numberOfYears] } }
および
view: persons_phone_number { dimension: areaCode {label: "Area Code"} dimension: number {} }
のような形で定義すればOKです。
ついでに、例のように persons の view 内で
dimension: citiesLived {hidden:yes} dimension: phoneNumber {hidden:yes}
のように階層化データおよび配列データを hidden にしておくと良いと思います。
ちなみにこのドキュメントページ、 かなり示唆に富んでいる ので一読をお勧めします。
各行に一意のキーがない配列の結合 などはたしかにそういったケースもあり得るか…と勉強になりました。
また、ここで登場する WITH OFFSET 自体は BigQueryで汎用的に使えるテクニック なのでぜひ覚えておきたいですね。
まとめ
今回は配列データのLookerでの扱い方についてまとめてみました。
配列データのみでなく、階層化データについてもあわせて扱いましたが、いずれも分析指向でDBを整備する上では使って損のない仕組みになっていると思います。
逆に開発指向でOLTPなDBを考えているときは、リレーションを活用することのほうが多いかとは思いますが、最近はスキーマレスなDBを活用する機会も増えましたので、皆さんのやり方や常識はまちまちなのかもしれません。
「DBに配列データや階層化データを入れるなんてあり得ない」なんて言って 化石認定 を喰らったり、 「なんでこのカラム配列にしなかったんスか?(笑)」 なんて煽られたりしないように、最新の動向に合わせたDB設計を行っていきたいところです…
